Console and API returns 403
Postmortem
Incident Started:2023-03-13 5:32 UTC
Resolution started: 2023-03-13 6:20 UTC
Incident Resolved:2023-03-13 09:22 UTC
Summary:
F5’s API Gateway service restarted and caused issues in processing rules for tenants, due to an increased amount of configuration objects. As a result, ~30% of the tenants were getting 403 errors while navigating F5 Console or using F5 APIs.
Root cause:
On Monday March 13th at 5:32pm UTC, one replica of the API Gateway service was restarted due to underlaying EC2 VM issues. This caused an issue during the initialization of RBAC rules for tenants and resulted in all requests reaching this instance with an error of 403 not authorized. It hit the system soft limit of, which has since been increased.
Incident flow:
On Monday March 13th at 5:32pm UTC, one replica of the API Gateway service was restarted due to underlaying EC2 VM issues. There was no error reported and systemic checks were working fine. At 6:20pm UTC F5 Operations noticed synthetic monitoring errors from our public APIs. Given the number of failures were low, F5 operations suspected issues were related to synthetic monitoring. At 6:36pm we started receiving tickets from F5 Support regarding 403’s being experienced via the F5 Console. At 6:50pm the F5 team decided to take immediate action and execute rollover procedures of the API Gateway service pods. The restart put all remaining replicas into a similar error state causing 403 requests for the remaining tenants, this was not expected.
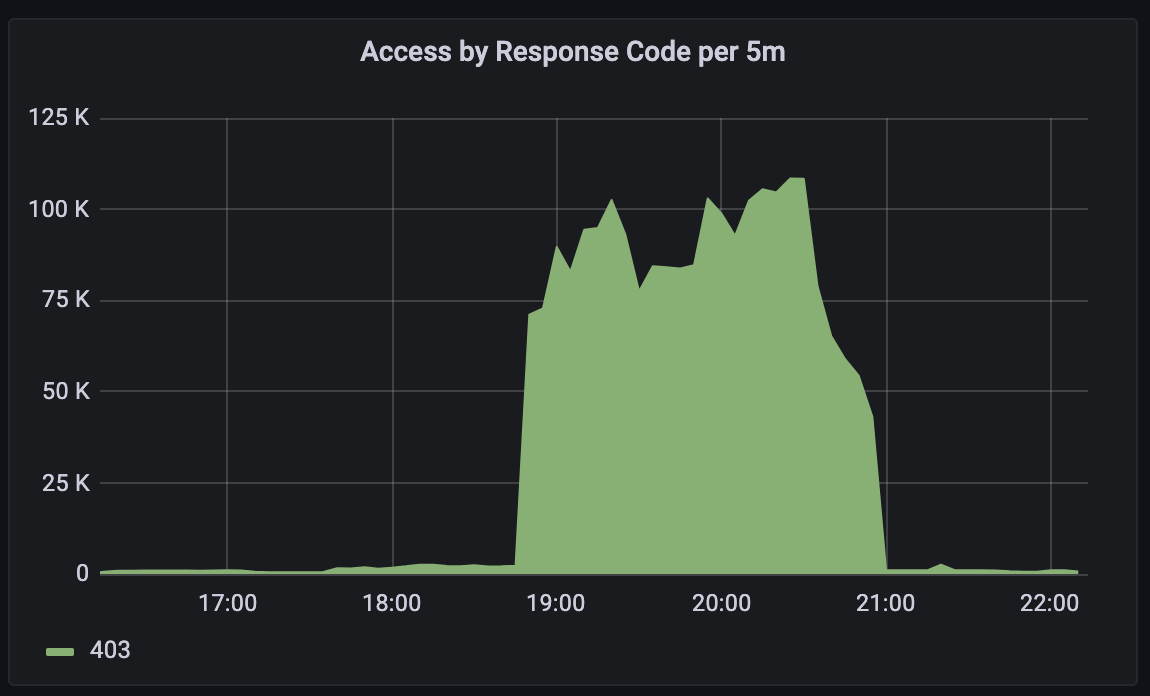
At the same time, a traffic spike of thousands of requests made the team think about a potential L7 DoS attack towards a single customer. It was later determined that the traffic spike was caused by a retry loop from a customer’s Continuous Delivery system. Continuous Delivery system was retrying due to 403 error and causing DoS. Further investigation pointed to the same root cause of the RBAC user rules size and the resulting 403 errors caused by the system soft limit.
This was identified at 8:40pm. We immediately raised the soft limit; the amount of traffic coming to API Gateway Service in combination of total restart caused another ~30 minutes delay in complete recovery. Thereafter, everything was successfully recovered at 9:22pm.
Corrective measures
In-progress. It will be updated after further analysis.